Abstract
- 数学问题在NLP领域难,因为会涉及到术语、符号和公式,因此解决数学问题需要一定的数学知识背景和逻辑推理能力。
- 本文提出了首个面向数学题理解的中文预训练模型 JiuZhang。受人类学习过程的启发,JiuZhang 被设计从基础到高级的课程预训练策略,逐步让模型完成从数学符号语义理解,到数学推理逻辑,再到自我检查与纠错的学习过程。
Introduction
现有的让语言模型适应数学文本主要有两种方法:
- 在常规的PLM继续MLM
- 重新为PLM设计预训练的任务
- Ps:
- PLM: Pre-train Language Model 预训练语言模型
- MLM: Masked Language Modeling 掩蔽语言建模,是预训练过程中的其中一个任务
当前的PLM具有以下限制:
- MLM是基于上下文语义进行建模的,而数学问题不仅依赖于上下文语义,很大程度上通过复杂的数学知识和逻辑推理来捕获“数学语义”。因此,这类型的PLM可能会对数学问题产生语言上合理但是数学上不正确的答案(例如: 1 + 1 = 3)
- 现有的基于数学问题的PLM是在英文语料上训练,可能不太适合解决一些非英语领域
为了解决上面的问题,本文提出了一个新的模型叫做 Jiuzhang,该模型包括一个共享的 Transformer 编码器,一个用于理解任务的解码器(-decoder)和一个用于生成任务的解码器(-decoder)。收集了一个大规模中文语料库喂给Jiuzhang吃🤤🤤,约有120w个高中数学问题。该语料库涵盖包括选择题、填空题和解答题等多种问题类型。
Jiuzhang 是怎么接收预训练的呢,大体来看有两个步骤:
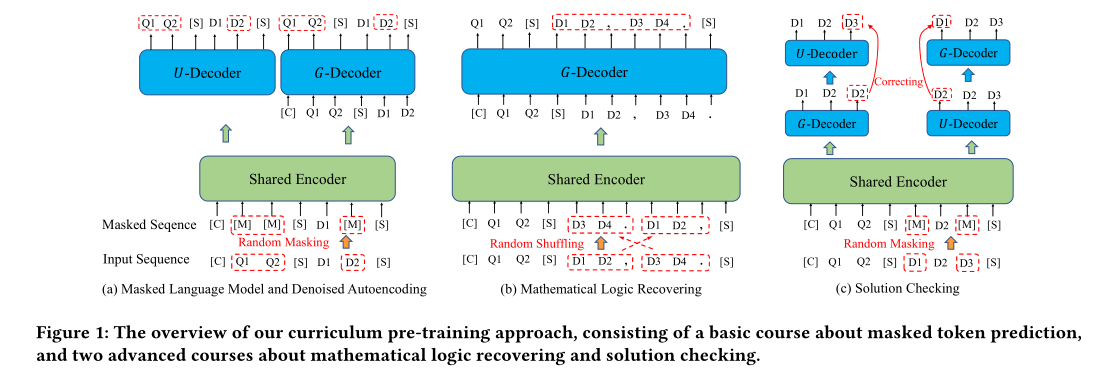
- 基础课程,目的是学习数学符号和文本语义关系的理解。设计了一个position-biased masking 的策略,大概率mask掉解决方案文本中靠近答案的那个token。
- 高级课程,目的是学习推理能力和答案纠错的能力。
- 推理能力:恢复被打乱的句子和公式
- 答案纠错:用两个decoder检测和纠正彼此生成的不正确的解决方案的文本。
Method
预训练语料库
一个数学文本包括 [问题描述] 和 [答案描述]。
假设定义数学文本为
$$
q = [t_{1}, t_{2}, t_{3}…t_{n}]
$$
其中t_{i} 可以表示 [普通文本] 或 [数学符号],当然一个连续的数学公式也可以定义成
$$
f = [t_{1}, t_{2}, t_{3}…t_{l}]
$$
模型架构
作者参考了CPT的做法有三个玩意:理解文本的encoder(shared Transformer Encoder),理解任务的decoder (U/G Decoder),负责生成任务的decoder
shared Transformer Encoder (10 layer)
跟普通的标准的Transformer中Encoder一样,有一个enbeddding 和多个Encoder层
Enbedding layer:
$$
E = E_{T} + E_{P}
$$$$
E_{T} \in R^{n \times d}, E_{P} \in R^{n×d}, 其中d为嵌入维度
$$Encoder layer: 叠加了L个encoder
U/G Decoder (2 layer)
U-Decoder(Understanding Decoder): 理解用Decoder,双向attention结构,类似于Encoder架构。该模块输入Encoder得到的表示,输出MLM的结果。目的是增强理解任务。
G-Decoder (Generation Decoder): 生成用Decoder,正如BART中的Decoder模块,利用encoder-decoder attention与Encoder相连,用于生成。
需要注意的是,此架构设计来源于CPT。文中描述两个Decoder会增加模型的参数量,同时,S-Enc如果太浅,就无法发挥共享Encoder的优势。因此,这两个Decoder被设计的很浅(称为unbalanced design)。实验发现,这样的深层Encoder,浅层Decoder结构同时保证了下游任务的性能和使用的方便灵活性。
训练方法
跟我们人类学习一样,JiuZhang接收两种类型的学习,分别是基础课程和高级课程:
- 基础课程,目的是学习数学符号和文本语义关系的理解。设计了一个position-biased masking 的策略,大概率mask掉解决方案文本中靠近答案的那个token。
- 高级课程,目的是学习推理能力和答案纠错的能力。
Basic Course: Masked Token Prediction
两个任务,分别是掩蔽语言建模MLM 和 去噪自动编码 DAE
MLM:
由U-Decoder来完成,token位置越靠后被mask的概率越高。因为作者认为在推导的过程中前面的步骤大多数是铺垫,真正影响结果的是后面的步骤
由于是中文语料,所以用全词mask的策略
loss定义如下:
$$
L_{MLM} = \sum_{t_{i}\in V_{mask}}-\log p(t_{i}\mid\tilde{x};\theta_{E},\theta_{U})
$$$$
其中V_{mask}表示被mask的词表空间;\
\tilde{x}表示被mask后的句子序列(问题+推理答案);\
p(t_{i}\mid\tilde{x})表示模型预测中被mask后的token的概率
$$
DAE:
由G-Decoder来完成,预测下一个token
loss定义如下:
$$
L_{DAE} = \sum_{i}-\log p(t_{i}\mid t_{<i},\tilde{x};\theta_{E},\theta_{G})
$$$$
p(t_{i}\mid t_{<i},\tilde{x})表示模型预测中被mask后的token的概率;\
\theta_{X}表示当前loss需要更新模块X的参数
$$
Advanced Course: Mathematical Logic Recovering
两个任务,分别是重排打乱后的句子 Shuffled Sentence Recovering(SSR) 和 重排打乱后的公式 Shuffled Formulas Recovering (SFR)
SSR:
由G-Decoder来完成,在给定[问题]的前提下打乱[正确答案]句子对的顺序,然后让模型还原原始内容(不是顺序)
loss定义如下:
$$
L_{SSR} = \sum_{i}-\log p(t_{i}\mid t_{<i},\tilde{d};\theta_{E},\theta_{G})
$$$$
\tilde{d}表示打乱顺序后的[正确答案];\
p(t_{i}\mid t_{<i},\tilde{d})表示模型预测中第i个位置的句子
$$
SFR:
由G-Decoder来完成,对于[正确答案]中带有[公式]的部分,我们打乱[公式]的顺序,然后让模型还原原始内容(不是顺序)
loss定义如下:
$$
L_{SFR} = \sum_{i}-\log p(t_{i}\mid t_{<i},\tilde{d_{F}};\theta_{E},\theta_{G})
$$
$$
\tilde{d_{F}}表示打乱顺序后的[公式];
p(t_{i}\mid t_{<i},\tilde{d_{F}})表示模型预测中第i个位置的公式
$$the logic-based pre-training objective
$$
L_{AC} = L_{MLM} + L_{DAE} + L_{SSR} + L_{SFR}
$$
Advanced Course: Solution Checking
对于数学问题来说,解决问题的步骤是很重要的。为了让模型得到正确的解决方案,应该仔细检查输出的 [解决方案]
Dual-Decoder Solution Checking (SC)
首先,按照Basic Course的方法mask部分掉 [解决方案],称之为 [被破坏的解决方案]
然后,分别让U-Decoder 和 G-Decoder来还原 [被破坏的解决方案],分别称为dU和dG
接下来,让U-Decoder来检查dG,让G-Decoder来检查dU, loss定义如下
$$
L_{USC} = \sum_{i}{-\log p(t_{i} \mid \tilde{d_{G} ; \theta_{E}}, \theta_{U})}
$$$$
L_{GSC} = \sum_{i}{-\log p(t_{i} \mid t_{<i},\tilde{d_{U} ; \theta_{E}}, \theta_{G})}
$$另外,为了防止模型忘记之前 “课程”, 还加了两个loss。所以,总loss为
$$
L_{SC} = L_{MLM} + L_{DAE} + L_{USC} + L_{GSC}
$$最后,为了增强模型的纠错能力。
- 模型需要区分token是否不正确,然后纠正这些token。
- 模型需要自己检查自己的生成是否正确
小讨论
- 作者的卖点不是把模型做大来增强数学能力,相反,作者的模型才121M个参数
- 作者认为给JiuZhang安排从基本到高级循序渐进的三个学习任务类似于现实生活中人类的学习过程,这样有助于模型性能。
Experiments
高中数学教育中的九项任务进行实验
Experimental Setup
- 预训练语料:
- 来自于“智学”网站上的120w+的数学问题。
- 将数学公式转化为latex
- 删除特殊字符和空格
- 用jieba分词
- 九项任务:三项分类任务、两项检索任务、两个问答任务和两项分析生成任务
- 知识点分类KPC
- 问题相关分类QRC
- 问答匹配QAM
- 相似问题检索SQR
- 问答检索QAR
- 单选题MCQ
- 填空题BFQ
- 单选分析题CAG
- 天空分析题BAG
- 将上述九项任务进行分类:
- 基础课程:contains KPC, QRC, QAM, SQR and QAR
- 高级课程:contains MCQ, BFQ, CAG and BAG
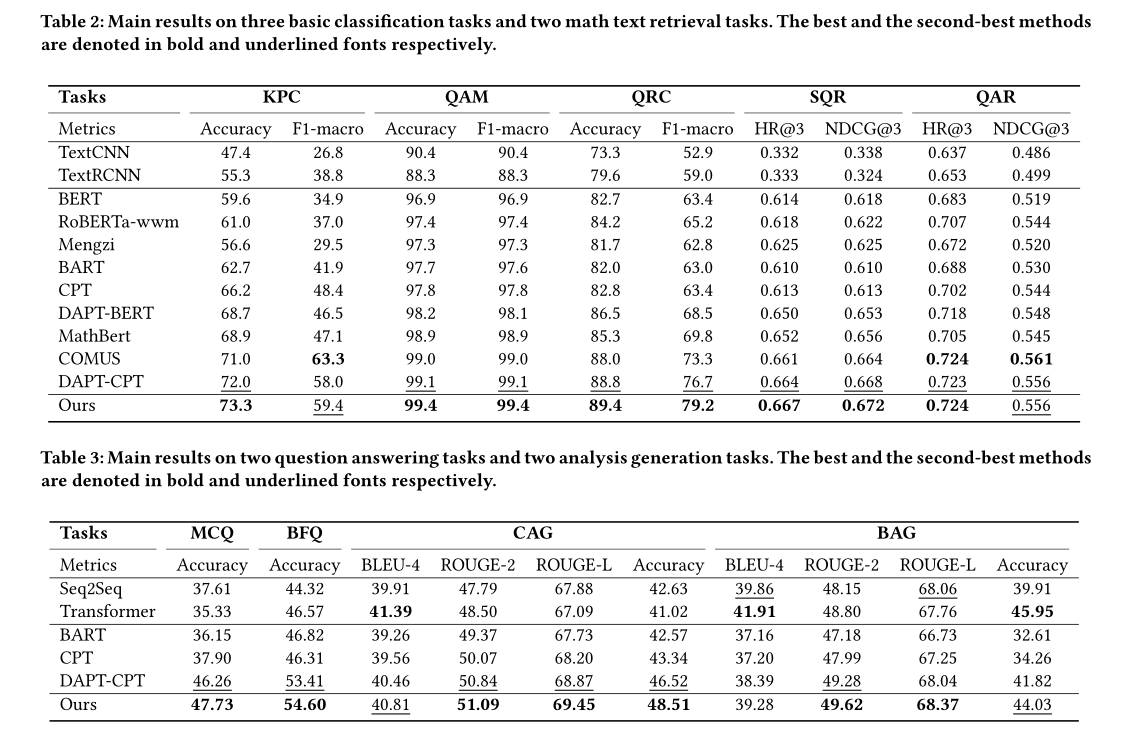
Main Results
Ablation Study
作者设计了三组消融实验:
- 只学习其中一个课程;
- 将课程学习顺序反着来;
- 用多任务学习来串联这三个课程。
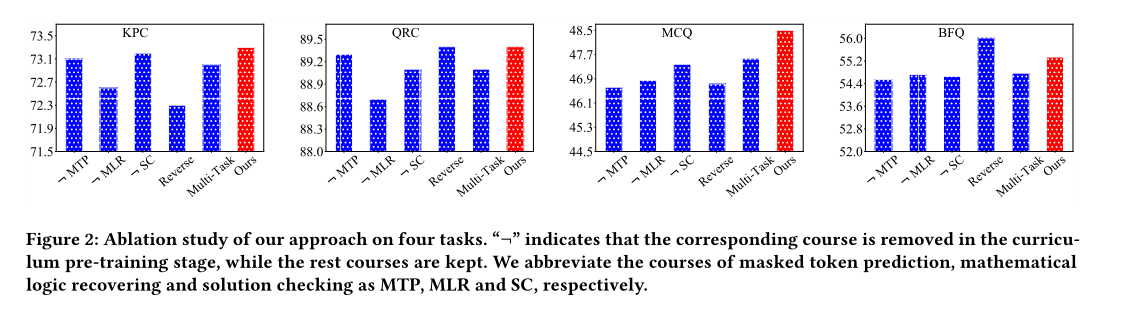
结果有点大跌眼镜😅😅😅,可以看到在 [问题相关分类] 和 [填空题] 这两个数据集中,将课程学习顺序反着来学的结果比正着来结果好。作者对此表示advanced-to-basic的顺序可能更适合做填空题(感觉解释地很牵强,没有正面回答)😶😶
Online A/B Test
什么是AB测试?
- 可以简单理解为将一群人分成两类,就是为同一个目标制定两个方案(比如两个页面),让一部分用户使用A方案,另一部分用户使用B方案,根据指标记录下用户的使用情况,看哪个方案更符合目标。
本文的AB测试是干什么?结果如何
“智学”网站上有相似问题推荐功能,作者将JiuZhang部署上“智学”然后接管这个推荐功能给用户推荐
用户收到推荐后判断是否这个推荐跟问题相关
结果表示大部分用户认为JiuZhang推荐功能更合理
